There are many ways to store data. There are text files, CSVs (Comma Separated Values), excel tables and so on. They all have their pros and cons. But in this blog post, I am going to talk about one server-based database: Postgres.
I will walk you through the installation of a working environment and a complete example of how one can go from python objects to a database.
What are the needs ?
A library that can convert objects to a data structure understandable by databases, this is called an ORM (Object Relational Mapper). For this we will use the python library SQLAlchemy. It does more than just translating objects from python to databases' data structures, it abstracts away many low level concepts such as connection, querying, and it offers several ways to interact with databases.
Using SQLAlchemy efficiently leads to more readable and easy-to-maintain code. A downside though, I think, is, it is not advisable to use it when we want to learn about SQL. Even though it offers the possibility to work with raw SQL queries.
A database where we'll store our data for later ease of access and querying. Rather than installing the full fledge PostgreSQl, we are going to use a dockerized version of it. Docker makes software installation very easy and takes away all the pain that comes often with installing softwares.
All you need is to have it installed on your machine. For installation guide, go here. And to get the docker, this medium post does a good job.
A python Data base API for communicating with PostgreSQl. You can find a list of options here. For this post, we are going to use psycopg2. SQLAlchemy needs this to properly communicate with the Postgres database.
[Optional] A virtual env which will contain only the necessary packages and where we'll do all the programming work.
SQLAlchemy ORM core concepts
At its core, there are Engines. As mentioned on the official website, it is the starting point for any SQLAlchemy application. It contains all the necessary stuffs to interact with a DBAPI (for those interested, you can find here, the full operations for the Python DBAPI) by making them accessible anytime there is a need.
Another core concept for the SQLAlchemy ORM is Session. It is very a convenient technical solution that makes the data persistence easy enough to avoid the user manually reporting all the changes to the created objects. All the queries are dealt with through sessions. For that purpose, it needs to have connection established with the database all the time, and whenever you want to affect changes to existing data or to evaluate queries, a simple notification sent is enough (through an implementation of the DBAPI commit or rollback). It thus works in common with the Engine.
The final concept I would like to talk about before getting to the practice is Table. Creating tables via the SQLAlchemy ORM is as easy as creating classes. The only thing to do is to inherit from a base class which notifies SQLAlchemy that the class should be treated as the definition of a database table.
A complete walk through an example
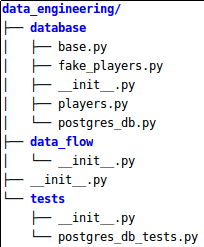
The example project will consist of storing some information about football players in a Postgres database using the SQLAlchemy ORM. To do this I created a project with the following structure:
a base file where are defined the configurations: Engine, Session and models base class.
a model file where is defined the table for players.
a class containing useful queries for our needs.
a fake player generator file using a very useful library: Faker.
The first thing to do is to define the configurations to use in order to communicate with the database. Here is the code which does that:
After doing that, we can now define the table associated to players in a declarative way.
Now we can define all the operations we want to handle through SQLAlchemy on the database (currently on the players table). This is a class containing some of the operations we can do.
All this done, for tests purpose and to be able to store many players still avoiding the tedious work to create all of them by hand, we need a data generator.
It is now very easy to test all these. Of course, for this to work, the Postgres should be accessible.
Summary
In this blog, we looked at some concepts of ORM and dive into a practical session using the python library SQLAlchemy to interact with a Postgres database to manipulate a model of football players. We saw how powerful the SQLAlchemy ORM is and how clean it makes the code, avoiding all the intricacies of raw SQL queries.
Now that we have some data available in a database, the next step is to build a data flow around this using a tool such as apache beam.
I really hope you enjoyed this, don't hesitate to send comments.
Note: All the code is available on my Github here.